par : Thalita Cirino do Nascimento, parcours « Chemoinformatics and Physical Chemistry », Milan-Strasbourg, 2022
J’ai commencé à m’intéresser à la chimie au lycée, plus particulièrement à la compréhension de l’origine et de l’évolution de la vie. En lisant des articles de recherche dans ce domaine, je suis tombée sur une interview de Noelia Ferruz de l’Institut de Biologie Moléculaire de Barcelone (IBMB). Ce qui m’a intrigué dans le travail de Noelia, c’est son approche innovante inspirée par la façon dont la nature a "conçu" au fil de l’évolution une variété de protéines ayant des fonctions et des topologies différentes.
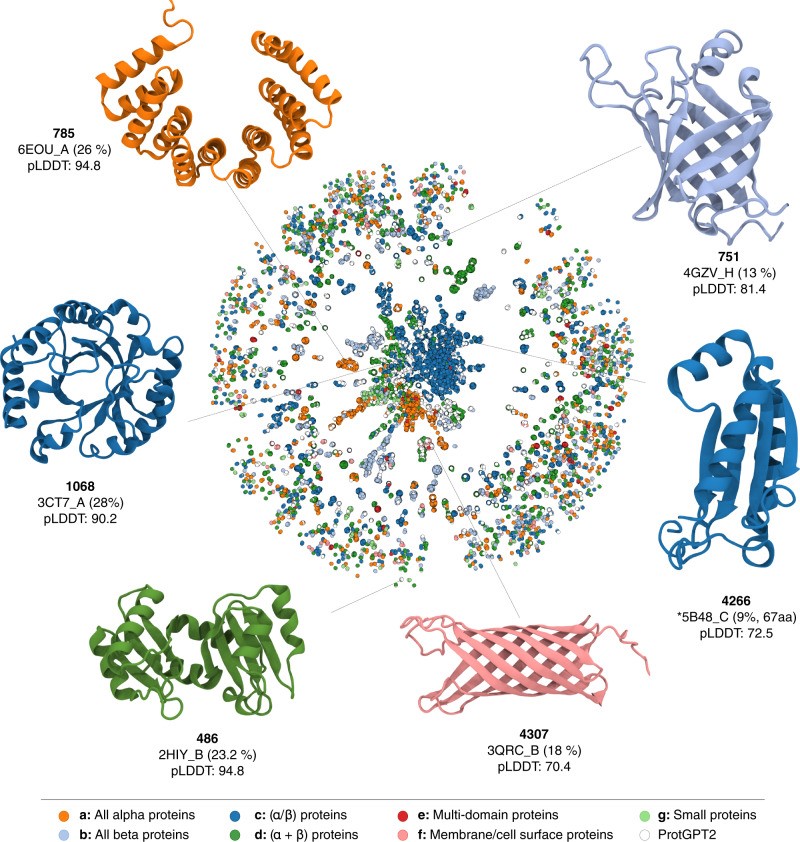
En effet, les peptides et les structures protéiques ont évolué par mutations et recombinaisons qui se sont accumulées pendant plus de 3 milliards d’années. Cela permet au vivant d’explorer un immense espace de séquences de protéines pour trouver de nouvelles fonctions biologiques. Noelia Ferruz a combiné cette compréhension de l’évolution moléculaire avec des modèles de traitement du langage naturel (NLP), comme le GPT-3, qui peut générer un texte qui aurait pu être produit par un être humain après avoir "lu" des millions de pages web et de livres. Une protéine étant représentée par une séquence de lettres, un modèle pouvant être entraîné de la même manière sur une base de données massive de plus de 50 millions de séquences de protéines naturelles a été mis au point : le ProtGPT2 [1]. Ce modèle intègre de façon implicite des règles sur la façon dont les acides aminés doivent s’enchaîner et, contrairement aux structures de novo conçues précédemment, les protéines de ProtGPT2 reproduisent la complexité des protéines naturelles avec des motifs de repliement et des boucles plus longues nécessaires à l’interaction avec d’autres molécules et à la fonctionnalisation (figure 1). Toutefois, la recherche de ces séquences dans les bases de données a révélé que les protéines artificielles et naturelles sont très éloignées les unes des autres : plutôt comme un cousin au troisième degré que comme un frère ou une sœur. Ceci suggère que ProtGPT2 ne se contente pas de copier des protéines existantes, mais qu’il combine des blocs d’acides aminés d’une manière originale.
Par conséquent, ProtGPT2 présente un potentiel en tant que modèle génératif capable d’explorer rapidement de nouvelles zones de l’espace des séquences de protéine. Grâce à de nombreuses prédictions informatiques, l’équipe de Noelia Ferruz fournit des éléments tendant à montrer qu’une forte proportion de ces séquences peut se replier en structures moléculaires stables et fonctionnelles ressemblant à celles que l’on trouve dans la nature. Bien qu’elle dépasse le cadre de l’étude 2022, une telle confirmation expérimentale est nécessaire avant que des conclusions définitives puissent être faites sur le repliement et les activités des protéines générées par ProtGPT2.
1. Ferruz, N., Schmidt, S. & Höcker, B. ProtGPT2 is a deep unsupervised language model for protein design. Nat Commun 13, 4348 (2022). https://doi.org/10.1038/s41467-022-32007-7